
Troubleshooting K3s: Semua Pod Rusak Setelah Reboot Karena CNI Flannel

Pendahuluan
Bayangkan sebuah cluster Kubernetes yang kemarin masih berjalan normal. Semua service aktif, storage Longhorn stabil, dan aplikasi berjalan tanpa masalah.
Lalu server di‑reboot.
Setelah server kembali online dan kita menjalankan:
kubectl get pods -A
Hampir seluruh pod berubah menjadi:
UnknownContainerCreatingError
Cluster terlihat seperti “mati”.
Artikel ini menceritakan kasus nyata troubleshooting pada cluster K3s ketika network plugin Flannel gagal start setelah reboot, dan bagaimana akhirnya cluster dipulihkan dengan migrasi ke Calico CNI.
Artikel ini ditulis dengan gaya praktis dan humanis agar mudah dipahami oleh engineer yang mengalami situasi serupa.
Gejala Awal
Setelah server reboot, hampir semua pod tidak berjalan.
kubectl get pods -A
Contoh output:
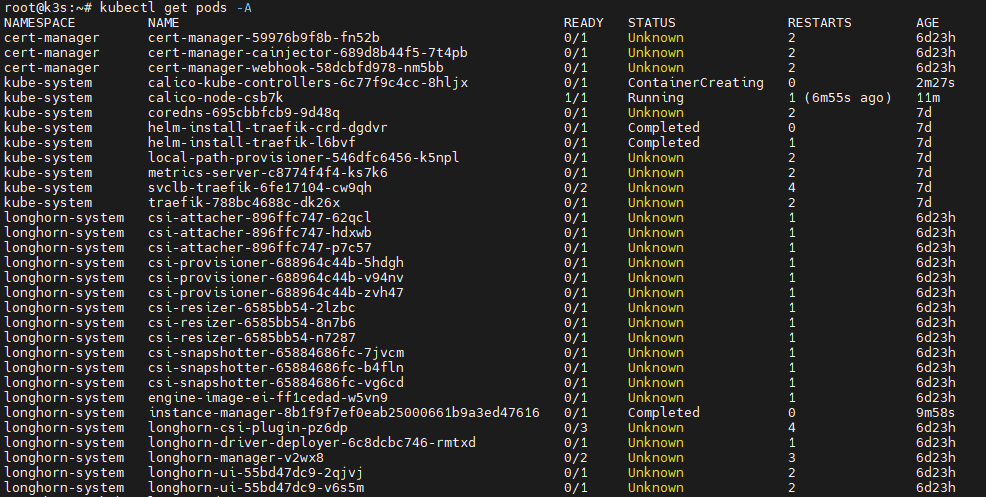
Sebagian pod lainnya terlihat stuck di ContainerCreating.
Ini biasanya tanda bahwa network cluster tidak siap.
Investigasi Masalah
Untuk mencari penyebabnya, kita melihat event pada pod.
kubectl describe pod nama pod -n kube-system
Dari event terlihat error berikut:
NetworkPluginNotReady
Network plugin returns error: cni plugin not initialized
Log sebelumnya juga menunjukkan:
plugin type="flannel" failed
failed to load flannel subnet.env
/run/flannel/subnet.env: no such file or directory
Artinya:
- Flannel gagal start setelah reboot
- File
/run/flannel/subnet.envtidak dibuat - Kubernetes tidak bisa membuat network sandbox untuk pod
Jika network tidak siap, Kubernetes tidak dapat menjalankan container.
Akibatnya hampir semua pod berubah status menjadi Unknown.
🧠 Diagram Arsitektur CNI (Flannel vs Calico)
Sederhananya, CNI bertanggung jawab membuat network untuk pod.
Arsitektur Flannel:
Pod
│
veth
│
cni0 bridge
│
flannel overlay network
│
node network
Arsitektur Calico:
Pod
│
veth
│
calico interface (caliXXX)
│
BGP / VXLAN
│
node network
Perbedaan utama:
| Feature | Flannel | Calico |
|---|---|---|
| Network policy | Tidak native | Native |
| Performance | Baik | Lebih cepat |
| Routing | Overlay | BGP / VXLAN |
| Production usage | Small cluster | Enterprise |
⚠️ Kenapa K3s + Reboot Sering Membuat Network Rusak
Beberapa alasan umum:
1. /run adalah tmpfs
Folder ini akan hilang setiap reboot.
Flannel menyimpan state penting di:
/run/flannel/subnet.env
Jika flannel gagal membuat file ini saat startup, cluster tidak punya network.
2. Race Condition Saat Boot
Kadang urutan boot seperti ini:
kubelet start
↓
pod dibuat
↓
CNI belum siap
Akhirnya pod gagal membuat network sandbox.
3. Residual Network State
Jika sebelumnya pernah mengganti CNI atau network state rusak, kubelet bisa mencoba menggunakan plugin lama.
Solusi
Solusi yang digunakan adalah:
- Disable Flannel
- Bersihkan state network lama
- Install Calico
- Restart pod Calico
1. Disable Flannel di K3s
Edit konfigurasi K3s:
nano /etc/rancher/k3s/config.yaml
Tambahkan:
flannel-backend: none
disable-network-policy: true
Restart K3s:
systemctl restart k3s
2. Bersihkan Network Lama
Stop K3s:
systemctl stop k3s
Hapus state network:
rm -rf /etc/cni/net.d/*
rm -rf /var/lib/cni
rm -rf /run/flannel
Hapus interface lama:
ip link delete cni0 2>/dev/null
ip link delete flannel.1 2>/dev/null
Start kembali K3s:
systemctl start k3s
3. Install Calico
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/calico.yaml
Cek pod:
kubectl get pods -n kube-system
4. Restart Pod Calico
Kadang pod masih membawa state network lama.
Solusinya cukup restart pod:
kubectl delete pod -n kube-system calico-kube-controllers-xxxx
kubectl delete pod -n kube-system calico-node-xxxx
Pod baru akan dibuat otomatis oleh Kubernetes.
Verifikasi Cluster
Cek node:
kubectl get nodes
Harus menjadi:
Ready
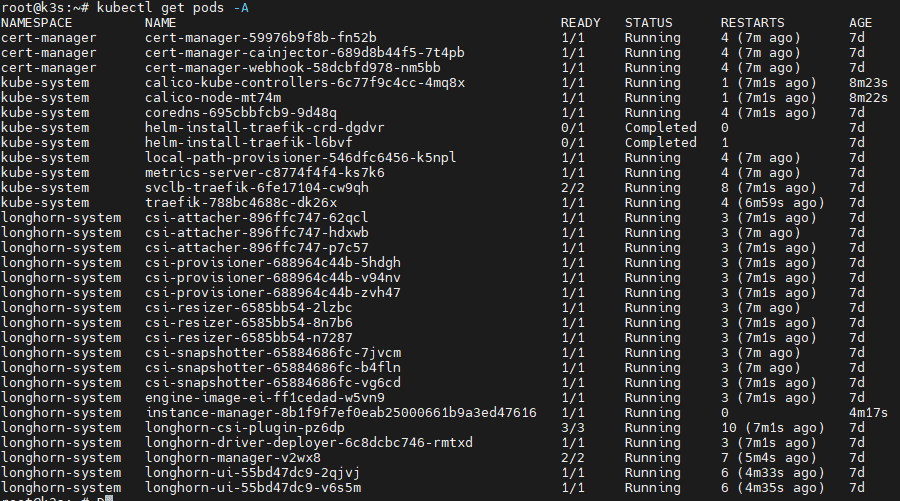
Cek semua pod:
kubectl get pods -A
Pod harus berubah menjadi:
Running
📊 Best Practice K3s Production Setup
Beberapa rekomendasi untuk cluster production:
1. Gunakan Calico atau Cilium
Lebih stabil untuk cluster production dibanding Flannel.
2. Disable Swap
swapoff -a
3. Gunakan Monitoring
Tools yang disarankan:
- Prometheus
- Grafana
- Loki
4. Backup Longhorn
Pastikan backup volume storage dilakukan secara berkala.
5. Pisahkan Control Plane
Untuk production cluster lebih besar, gunakan:
3 control plane node
✍️ Penutup – Cerita Nyata dari Insiden Ini
Kasus ini cukup menarik karena awalnya terlihat seperti seluruh cluster Kubernetes rusak.
Padahal penyebabnya hanya satu hal kecil:
Flannel gagal membuat subnet.env
Karena Kubernetes sangat bergantung pada CNI, satu komponen kecil ini bisa membuat seluruh cluster terlihat mati.
Setelah network diperbaiki dan Calico di‑deploy, seluruh pod kembali berjalan normal.
Ini menjadi pengingat bahwa dalam Kubernetes:
Jika semua pod tiba‑tiba mati, hampir selalu masalahnya ada di network atau CNI.
Semoga artikel ini membantu jika suatu hari cluster K3s kamu tiba‑tiba rusak setelah reboot.

Dalam dunia Cloud Computing dan DevOps, tiga istilah yang paling sering kita dengar adalah Virtual Machine (VM), Container, dan Pod….

Monitoring sangat penting untuk memastikan aplikasi berjalan stabil. Dengan stack Prometheus + Grafana + Loki + Promtail, kita bisa memantau…